1
AI
6349 readers
3 users here now
Artificial intelligence (AI) is intelligence demonstrated by machines, unlike the natural intelligence displayed by humans and animals, which involves consciousness and emotionality. The distinction between the former and the latter categories is often revealed by the acronym chosen.
founded 5 years ago
2
3
cross-posted from: https://lemmy.world/post/45435064
So I decided to (literally) TEST them!
The result?
...well see the wonders of Telegram AI for yourselves 🤣 🤣 🤣

{kind=link}
4
5
1
Z.ai unveils GLM-5.1, enabling AI coding agents to run autonomously for hours
(www.computerworld.com)
6
7
1
1 In 5 Boys Know Someone Their Age Who's In A Relationship With An AI Chatbot
(www.huffingtonpost.co.uk)
8
9
{kind=link}
10
11
12
13
1
Daddy, what did you pretend to do in the war? — Daoist Methodologies [2026-03-27]
(xianyangcb.substack.com)
A fun little recounting of the cultural grift of Silicon Valley, a stitched-together pile of zombies propped up by the world's largest private banks.
Expand article
[

{kind=link}
Over the past year or so, many idealistic AI researchers have decided that if ASI is coming they would rather go all-in on building their own rather than spend the crucial months changing button colours for FAANG. The sector is awash with money. There Has Never Been A Better Time To Start A Startup.
They immediately discover that fundraising requires them to stop building AI models and instead devote their time to acting like the kind of person who builds AI models.
[

{kind=link}
If your instinctive response to this is “Boohoo. Some Stanford Grads have to perform the social codes of their own sector in return for tens of millions of dollars. If you hate it so much why not just build something so good that the funders don’t care what you look and sound like?” This is to fundamentally misunderstand the point of the process. The point of this exercise is not to create something good. Have you used VC-funded software lately? It is to create a betting vehicle for Y Combinator’s ever growing down-line of greater fools.
For the most part, you don’t raise money by being good. You raise money by fitting the “founder who will still be luring in degenerate gamblers at series B” stereotype.
[

Lewis 🇺🇸@ctjlewis
It feels almost like YC has hijacked incentives to the point where other institutions are being damaged. We expect Stanford to produce brilliant researchers, not box-checking faggots who are all clones of each other, doing “prompt to sales leads” bullshit.


Finn Mallery @fin465
We used Delve for compliance and I have no regrets everyone acting all high and mighty about compliance when 99% of you would pick the fastest and easiest option every time #IStandWithDelve https://t.co/zhnhk5rqLr
6:29 AM · Mar 21, 2026 · 946 Views
4 Replies · 2 Reposts · 33 Likes
](https://x.com/ctjlewis/status/2035242413631938765)
If you’re really good you can then skim off enough cash from the pot to build something actually novel and interesting - this is known as the Liang Wenfeng gambit - but such individuals are rare, and for a good reason: because it is incredibly difficult to Do The Thing and Pretend To Do The Thing simultaneously. Only a tiny proportion of people are capable of acting like they are able to run a frontier AI lab while also running a frontier lab, creating a market for lemons: You can either Do The Thing and not get paid for it, or Get Paid For The Thing and not do it. Choose one.
So why not move to academia? There’s no profit motive to corrupt incentives there. Surely it’s a better place to do pure research?
In fact, it’s far worse, and has been for much longer than venture capital.
The same problem of Simulating The Thing being more rewarding than Doing The Thing has existed in academia for decades. It can take years to come up with one genuinely revolutionary discovery, which often can be summarised in a few short pages of relatively simple language. This doesn’t give tenure committees much to work with. By contrast, a guy churning eight or nine long and unreadable papers claiming to add nuance to other people’s work looks like a productive researcher. He is legible to the tenure committee, and lo it is upon him that tenure is bestowed. This is then compounded by the peer review system. Whereas in Silicon Valley it is occasionally possible to squeeze past the gatekeepers by relying on personal debt until you are so impressive that the market can’t ignore you, in academia the better you are the more likely you are to be ignored. The peer review system ensures that anyone who comes up with a genuinely paradigm-shifting innovation is first forced to secure the approval of a disparate group of people whose careers will likely be destroyed should he happen to be proven right. Sure, you can spend 20 years publishing p-hacked results and kissing the rear ends of incumbents in the hope of one day being permitted to have an idea, but fewer and fewer individuals expecting to experience significant ideas are particularly enthusiastic about this strategy, and thus they filter themselves out.
These are not bullshit jobs - jobs that serve no socially useful purpose beyond being a sort of New Deal for the middle classes - rather they are activities that theoretically have some utility but have been so hollowed out by Goodharted incentive structures that they now fulfill the opposite of their intended function.
Where the early VCs were independently wealthy boomers who distributed cash according to vibe-driven heuristics that were close enough to true randomness to ensure an occasional 100x win to balance out the dozens of dogs. However, as the strategy proved effective they were able to hire research associates whose job description requires them to find similar unicorns but whose salaries incentivise them to pass only passing the least crazy-looking deals up to the committee: for them the risk of missing the next Uber is far outweighed by the risk of passing it up the chain and being laughed at because the boss thinks it’s a silly idea. Nobody gets fired for investing in IBM.
The gentleman-scholars, hobbyists and clerics who created modern academia were free to chase novelty precisely because their income did not depend upon it. Turning research into a remunerated activity was intended to grant impoverished geniuses access to the scientific process, but it turned out that willingness to work without a monthly stipend was a load-bearing quality filter. A researcher receiving a salary must conform to his paymasters’ perceptions of what his job should look like. One doing it for the love of the game is accountable only to the truth (and his wife).
Once you spot the mechanism you start seeing it everywhere. If you describe an illness to ChatGPT it will quite often end its diagnosis by asking whether you would like it to provide a summary of your symptoms that is likely to convince your doctor to treat them. It is not sufficient to be ill, you must also perform illness with a level of verisimilitude at least equal to that of the legions of hypochondriacs that wander from medic to medic optimising their simulation on dense reward-based feedback. In this game, naturally, you are at a significant disadvantage, since the you are actually ill and performing below your best, while they are not. Gradually actual sufferers turn to AI + grey-market Indian pharmacies, and the entire health system becomes a charity fund for inserting heavy-duty tranquiliser pills into the mentally ill. (So arguably it does have a useful function, just not necessarily the one it claims.)
The process is quasi-universal because it has such an effective flywheel. Each round: mimic population improves at signaling → threshold rises → producers divert more time to signaling → substance production falls → outcome-based evaluation becomes noisier → evaluators double down on legibility heuristics → which rewards signal more → which grows the mimic population.
[

B/U Karsten@BU_Karsten
@raastapopoulos Turns out convincing YC to fund your startup requires the same qualities you need for scamming.
2:29 PM · Mar 20, 2026 · 31.8K Views
3 Replies · 3 Reposts · 512 Likes
](https://x.com/BU_Karsten/status/2035000882090176804)
As the mimic population grows, the reference class for "real research" or "real illness" becomes increasingly contaminated. Evaluators who grew up in the mimic-dominated regime have fewer and fewer exemplars of genuine substance to calibrate against. The evaluator loses the ability to tell the difference, and each generation of evaluators has a worse calibration set than the last. Per Gresham’s law, bad money crowds out good money because they are interchangeable in exchange but the bad money is cheaper to produce. Here, signals crowd out substance because they are interchangeable in evaluation but signal production has lower opportunity cost for the mimic population.
But this raises a question: shouldn’t the mimics create an evolutionary niche for mimic predators? Specialist evaluators who sell their bullshit detection services?
In fact there are a few. Not auditors, who tend to be captured as soon as they are created, simply because in mass market situations the harm from providing an accurate report of a principal-agent conflict tends to be concentrated while the benefit is diffuse. Everyone in the US economy would have benefited from an accurate depiction of Enron’s finances, but only by a few dollars each. Enron benefited far more by keeping things secret, and thus it was Enron’s surplus that Arthur Anderson targeted.
Short sellers are a much better candidate. Recently they have done sterling work to expose massive fraud in Alzheimer’s research. A group of short sellers ran a concerted campaign to prove that research conducted by Dr. Wang Hoau-Yan for Cassava Biosciences was fraudulent. It was, but they were not regarded as public heroes for their efforts, instead they were panned for their conflict of interest. Incentivising malpractice is fine, but incentivising whistleblowing is beyond the pale, apparently.
Going forward, whistleblowers, just like authors, editors, and referees, will be asked to inform us of recent, ongoing, and potential conflicts of interest. Financial conflicts of interest will be considered and weighed in any follow-up investigative actions and especially in any communication to the whistleblowers. We may independently seek to verify whistleblowers’ potential conflicts. We will limit what information we share with whistleblowers, since advanced notice of news reports positions short sellers to take advantage of shifts in stock prices. There is a time sensitivity to short selling, so we feel the best approach for any journal is to be deliberate and cautious, and to exert due diligence in investigating any allegations of scientific misconduct or data/image manipulation.
So there’s no real market for radical truth, unfortunately, but it’s ok because you’re not going to commit malpractice. You’re just going to perform enough compliance to be granted access. Then you’ll reform the institutions from the inside. Just write a few papers bro. Just a little p-hacking. It’s not like it’s your topic. It doesn’t matter. You’re just doing it until you get tenure and can do some good work. Just a few more papers. Just a few more years.
The problem with this approach is that becoming successful at Thing X generally only earns you the right to do more of X. It doesn’t give you the latitude to do some Y, if anything it makes doing Y harder, since your time is now spoken for by X. Raising series A for a bullshit SaaS company doesn’t give you the leeway to build the cool frontier lab you always dreamed of, it weighs you down with obligations to people who all expect you to raise a series B.
The French bureaucracy has, over time, evolved a particularly effective version of this mechanism to pacify its notoriously fractious citizens. The state imposes extremely high taxes, but a canny and administratively literate citizen can claw back more than he pays in subsidies. Just a couple of forms and you might be back in the black with ten maybe even fifty euros extra for your trouble. Just a couple of forms bro. How long could it take?
Because most people (at least the ones who are not self-employed) do not see transaction costs as costs, they do not notice how much they are being asked to pay to access systems supposedly constructed for their benefit. More importantly they do not notice the rate of growth.
The end result is that every citizen has a second job filling out forms and is thus too busy trying to extract a few more euros of other people’s money to rebel. L’État, c’est la grande fiction à travers laquelle tout le monde s’efforce de vivre aux dépens de tout le monde.
The shock of sudden awareness may proceed from the realisation that the transaction costs now outweigh the benefits of access, but in recent years the opposite mechanic has predominated: the costs are the same but the benefits have cratered.
The moment of revelation usually creeps up quietly, when an individual realises that the most valuable thing he can buy with his reward points is the right stop thinking about reward points. A silent, distributed exit from an Omelas that crushed your inner child under an unending barrage of degrading formalism.
Private medicine. Private security. Home schooling. Vibe coding. Dubai.
Nowadays we don’t betray our countries because of ideological incompatibility or even for mercenary motives but because we are bored. I will do without the reward points thank you.
They post classified military documents to the War Thunder forums not because they disagree with their government’s military policy but because their primary community is the War Thunder forum and their primary identity is “person who knows correct tank armour specifications”.
[

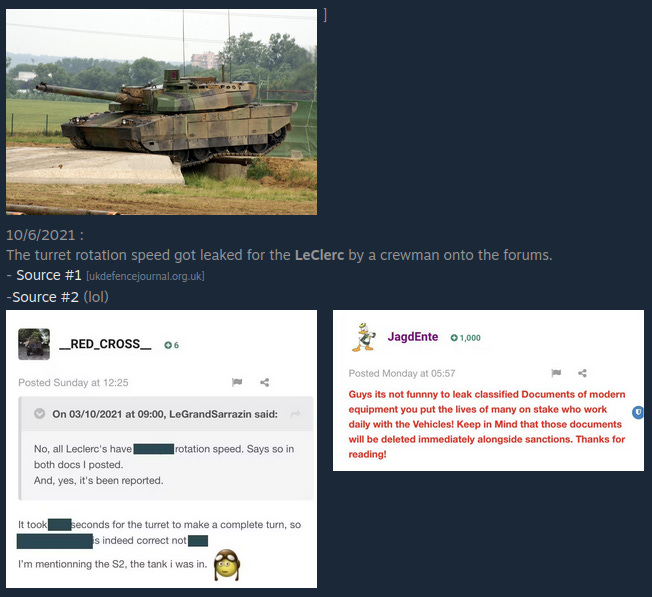{kind=link}
The classification system is a vague bureaucratic annoyance that exists in a different universe that he is forced to visit periodically but which contains no significant enticements to stay. The state secret is of less consequence than being Right On The Internet, and the leaker, once caught, is mildly surprised to find that others are still striving, like lost Japanese troops, to preserve it. “Really? You guys are still doing this? PepeCringeCigarette.jpg”
Most of the people who began homeschooling in the post-COVID years are not taking the Benedict Option and opting out of a society with which they disagree spiritually and ideologically. They’re just ordinary individuals who looked at the school system and concluded the institution wasn’t serious and wasn’t going to get serious and the transaction costs of engaging weren’t worth it.
It’s not a revolution, it's a one-star Yelp review, and maybe that’s as much consideration as our institutions deserve.
Tracing a universal mechanism across Silicon Valley, academia, healthcare, and bureaucracy: “the point of this exercise is not to create something good… You raise money by fitting the ‘founder who will still be luring in degenerate gamblers at series B’ stereotype.” Those who can actually do the work find themselves squeezed out by those who have mastered performing it. “Only a tiny proportion of people are capable of acting like they are able to run a frontier AI lab while also running a frontier lab, creating a market for lemons: You can either Do The Thing and not get paid for it, or Get Paid For The Thing and not do it.”
Academia proves worse. “It can take years to come up with one genuinely revolutionary discovery… This doesn’t give tenure committees much to work with. By contrast, a guy churning eight or nine long and unreadable papers claiming to add nuance to other people’s work looks like a productive researcher.” Peer review ensures that anyone with a paradigm-shifting idea must first secure approval from “a disparate group of people whose careers will likely be destroyed should he happen to be proven right.” What results are activities hollowed out by Goodhart’s law, fulfilling the opposite of their intended function.
The flywheel is self-reinforcing: “mimic population improves at signaling, the threshold rises, producers divert more time to signaling, substance production falls… evaluators double down on legibility heuristics, which rewards signal more, which grows the mimic population.” Short sellers act as rare “mimic predators,” but when they exposed fraud in Alzheimer’s research, “they were not regarded as public heroes… incentivizing malpractice is fine, but incentivizing whistleblowing is beyond the pale.”
The French bureaucracy perfected this to pacify citizens: “the state imposes extremely high taxes, but a canny and administratively literate citizen can claw back more than he pays in subsidies. Just a couple of forms bro. How long could it take?” The end result is that every citizen has “a second job filling out forms and is thus too busy trying to extract a few more euros of other people’s money to rebel.” The moment of revelation comes when one realizes “the most valuable thing he can buy with his reward points is the right to stop thinking about reward points.”
This produces a quiet, distributed exit—private medicine, homeschooling, “vibe coding,” Dubai—not from ideological conviction but because “we are bored.” The War Thunder leaker posts classified documents not out of malice but because “the state secret is of less consequence than being Right On The Internet.”
14
15
1
Is Ethiopia Ready for the Artificial Intelligence Era? — The Africa Hour Podcast [2024-02-22]
(afripoli.org)
Expand details
In this month's tenth episode, our host explores Ethiopia's quest for AI dominance, supported by local innovation and policy, amid lingering ethical issues.

Ethiopia is marketing itself as the leading artificial intelligence (AI) player in Africa. The country is not just mouthing off though – it has some credits to back its claim. Some parts of Sophia the robot were developed right in Addis Ababa. Several Ethiopian startups are also using AI to develop products like language apps focused on local languages. Ethiopia is covering its base on the policy side too, with a new artificial intelligence institute, and a national AI policy in the making. But does this east African country have what it takes to be the AI powerhouse while avoiding ethical problems?
Hruy Tsegaye is a leading AI voice in Ethiopia. He is a co-founder at iCog Labs, the first private AI/Robotics company in East Africa - and the CEO of Mindplex, a decentralized media platform. Hruy is also a prolific AI researcher, and has published multiple articles on the state of AI in Africa. You can find some of his pieces on how decentralised AI can help solve development problems here.
Abdullahi Tsanni is a science journalist currently reporting for the prestigious MIT Tech Review in Boston. His work, which covers a wide range of issues across technology, science and health, has appeared in publications like STAT News, Nature, and The British Medical Journal. His recent report on the startups leading the race in programming AI specifically for African languages like Amharic is here.
Finally, Dr Taye Girma is the Deputy Director General at the Ethiopian Artificial Intelligence Institute, and is one of the brains behind the upcoming national AI policy. The Institute is one of the first such government departments in Africa, and is working on how AI can help boost the health, finance, transportation and agriculture sectors. Dr Girma is one of the founders of the Institute, and is at the center of AI research and practice in Ethiopia. He is also a professor of Computer Engineering with a focus on AI at the Addis Ababa Science and Technology University.
Nation Strengthening AI Technology to Modernize, Enhance Efficiency: Institute Director-General: https://www.ena.et/web/eng/w/eng/_3633464
Whose Job Will AI Replace? Here's Why a Clerk in Ethiopia Has More to Fear Than One in California: https://theconversation.com/whose-job-will-ai-replace-heres-why-a-clerk-in-ethiopia-has-more-to-fear-than-one-in-california-216735
Grand Challenges Ethiopia: Catalyzing Equitable AI Use to Improve Global Health: https://www2.fundsforngos.org/latest-funds-for-ngos/grand-challenges-ethiopia-catalyzing-equitable-ai-use-to-improve-global-health/
The AI Startup Outperforming Google Translate in Ethiopian Languages: https://restofworld.org/2023/3-minutes-with-asmelash-teka-hadgu/
Ethiopian Artificial Intelligence Institutes Discusses Intellectual Property Rights for its Products: https://www.aii.et/ethiopian-artificial-intelligence-institutes-discuss-about-the-intellectual-property-rights-for-the-products-developed-by-the-institute/
African Union (AU) Continental AI Strategy for Africa: https://www.nepad.org/news/african-union-artificial-intelligence-continental-strategy-africa
A Sceptical Approach to the Future of AI and Emerging Technologies in Today’s Africa:https://medium.com/@Hruy.T/a-sceptical-approach-to-the-future-of-ai-and-emerging-technologies-in-todays-africa-d03abb04b8bf
The Future of AI Statistics in Africa - Is the Continent Really Ready?: https://www.isi-web.org/article/future-ai-statistics-africa-continent-ready#%3A%7E%3Atext=digital+solutions+into+their+statistical%2Csteps+to+formulate+AI+policies
Ethiopia is positioning itself as a leading artificial intelligence player in Africa, with local innovation—including components of Sophia the robot developed in Addis Ababa—and policy initiatives such as a new AI institute and a forthcoming national AI strategy. Guests on the episode include Hruy Tsegaye, co-founder of iCog Labs, Abdullahi Tsanni of MIT Tech Review, and Dr. Taye Girma, Deputy Director General of the Ethiopian Artificial Intelligence Institute. Dr. Girma notes that the institute is working on how AI can boost sectors including health, finance, transportation, and agriculture, while discussions also address ethical challenges and the development of AI tools for local languages such as Amharic.
16
17
1
Speeding Up the “Kill Chain”: Pentagon Bombs Thousands of Targets in Iran Using Palantir AI
(www.democracynow.org)
18
1
Texting with a random person may be more effective in alleviating loneliness than an AI
(www.sciencedirect.com)
19
20
21
22
23
24
25
view more: next ›